Cross join is one of the most powerful yet misunderstood operations in SQL, capable of generating massive datasets in seconds when used correctly. While it can unlock advanced analytical possibilities, it can also create performance nightmares if handled carelessly. Understanding how this operation works, when to use it, and how to control its output is essential for developers, data analysts, and database administrators who want to write efficient and scalable queries.
Structured Query Language provides multiple ways to combine data from different tables. Most developers are familiar with INNER JOIN, LEFT JOIN, and RIGHT JOIN, but fewer truly understand the implications of combining every row from one table with every row from another. This is where the cross join becomes both powerful and potentially risky.
Understanding the Concept Behind Cartesian Products
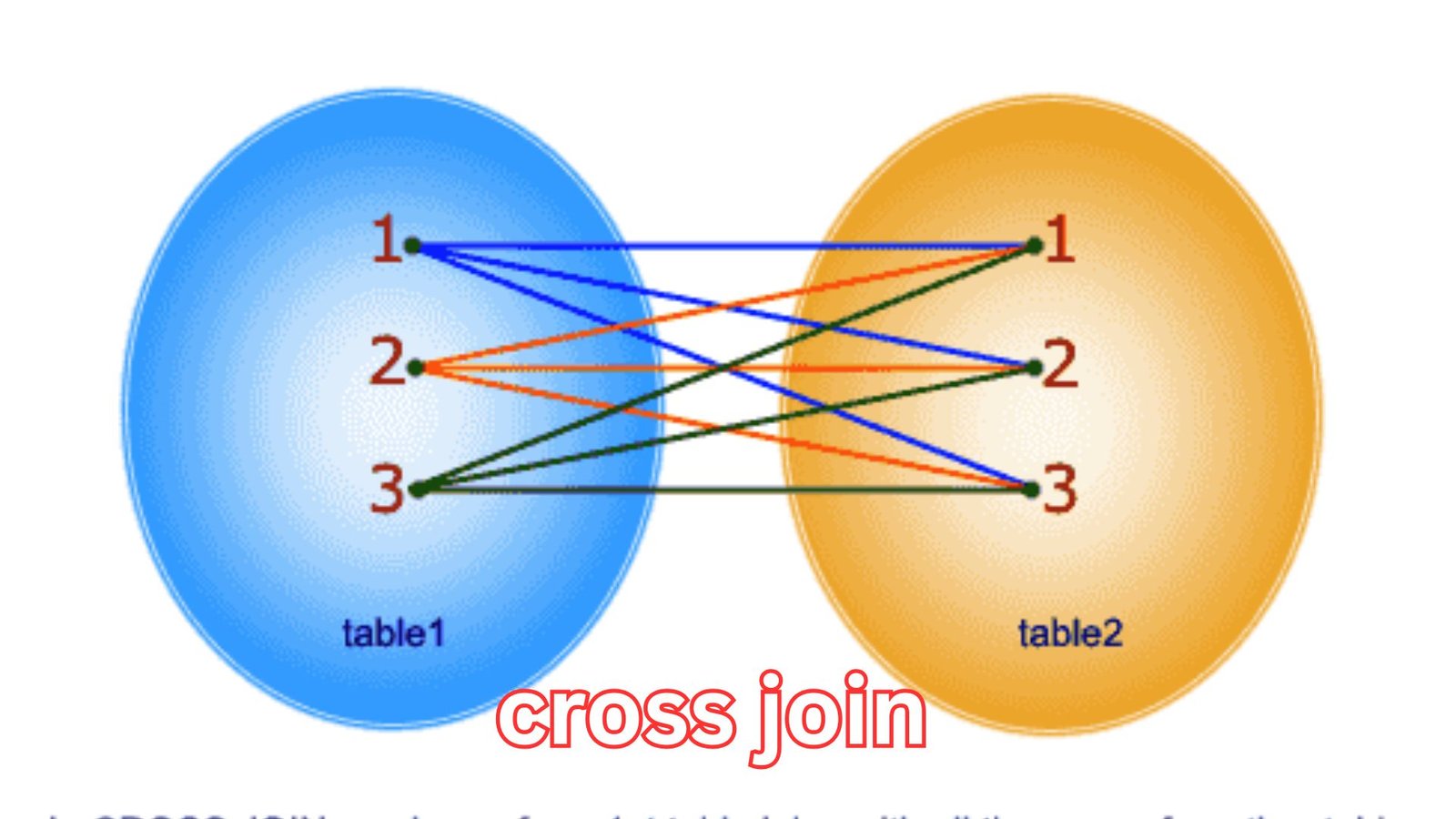
At its core, this join type produces a Cartesian product. That means each row from the first table is paired with every row from the second table. If one table contains 100 records and another contains 50, the result will contain 5,000 rows. The database engine does not filter or match rows based on a condition unless explicitly instructed afterward.
Unlike conditional joins, this method does not rely on matching keys. There is no ON clause specifying how rows relate. Instead, the output multiplies datasets together, forming all possible combinations. This makes it uniquely useful in specific analytical scenarios.
The mathematics behind it is straightforward but powerful. If table A has n rows and table B has m rows, the resulting dataset will contain n × m rows. This multiplicative behavior explains why even small datasets can quickly expand into massive outputs.
When a Cross Join Becomes Useful
Despite its intimidating nature, there are legitimate and strategic use cases for a cross join. One of the most common is generating combinations. For example, imagine creating all possible product-color combinations for an e-commerce catalog. If you have 10 products and 5 available colors, you need 50 unique combinations. This type of SQL operation is ideal for that scenario.
Another practical example appears in data simulation and testing. Developers often need to generate large synthetic datasets to stress-test applications. By combining two smaller reference tables, it becomes easy to produce thousands or even millions of rows for experimentation.
In reporting and analytics, it can also help when building calendar tables or pairing time intervals with events. Analysts may use it to associate every date with every store location, allowing later filtering for more refined reporting.
How It Differs From Other Join Types
It is important to distinguish this method from INNER JOIN or LEFT JOIN. Conditional joins require a matching column and filter rows based on logical relationships. The cross join, however, intentionally avoids that relationship at the start.
INNER JOIN returns only matching records between two tables. LEFT JOIN keeps all rows from the left table and matches available records from the right table. In contrast, the Cartesian approach produces every possible pairing, regardless of logical relationship.
Because of this fundamental difference, it is both simpler in syntax and more dangerous in execution. A missing condition in an INNER JOIN can accidentally turn into this behavior, leading to unexpectedly large result sets.

Syntax and Implementation in SQL
The syntax is straightforward and widely supported across major database systems such as MySQL, PostgreSQL, SQL Server, and Oracle. The general structure looks like this:
SELECT columns
FROM table1
CROSS JOIN table2;
Some systems even allow the same result by listing tables separated by commas, though explicit syntax is clearer and safer.
Although the statement is simple, understanding its impact on execution plans is critical. Database engines must compute all possible combinations before applying further filtering unless optimization shortcuts are available.
Cross Join in Real-World Applications
The cross join plays a significant role in advanced data modeling and business intelligence workflows. For example, in sales forecasting, analysts may need to combine every product with every projected quarter to build scenario-based models. This operation ensures no potential combination is overlooked.
It is also useful in educational environments where students learn relational algebra concepts. By seeing how two unrelated tables combine, learners gain a deeper understanding of how relational databases function internally.
In marketing analytics, pairing each campaign with every customer segment can help teams evaluate theoretical reach scenarios. After generating combinations, filters can refine the dataset based on eligibility criteria.
The key is intentional usage. When applied thoughtfully, it enables sophisticated analytical transformations that would otherwise require complex procedural code.
Performance Considerations and Potential Risks
One of the biggest concerns with cross join operations is performance. Because the output size grows multiplicatively, even moderately sized tables can generate enormous datasets. This can consume significant memory, CPU resources, and disk space.
For instance, combining two tables with 10,000 rows each produces 100 million rows. On production systems, such queries can slow down servers or even cause timeouts.
To mitigate these risks, developers should always estimate expected row counts before running queries. Applying WHERE clauses after the join can reduce final output, but it does not eliminate the cost of generating intermediate results unless the database optimizer can intelligently push filters earlier in the execution plan.
Indexes do not directly reduce the multiplication effect, but they can help improve filtering performance after combinations are formed.
Best Practices for Safe Implementation
Using cross join responsibly requires planning and awareness. Developers should test queries on small datasets before running them on production tables. Examining execution plans helps determine whether the database engine is efficiently handling the operation.
It is also wise to limit columns selected. Avoid using SELECT * when generating large combinations. Instead, retrieve only necessary fields to minimize memory usage.
When possible, introduce filtering conditions as early as feasible. Even though this join type initially produces all combinations, certain database optimizers may reduce workload when conditions are structured efficiently.
Another practical strategy involves temporarily limiting datasets with TOP or LIMIT clauses during testing. This prevents accidental overload during development.
Comparing Explicit and Implicit Syntax
Historically, SQL allowed listing multiple tables separated by commas in the FROM clause. Without a WHERE condition, this produces the same result as a cross join. However, this implicit style is less readable and more prone to errors.
Modern best practice recommends using the explicit CROSS JOIN keyword. It clearly communicates intent and prevents confusion among team members reviewing the code.
Explicit syntax also makes debugging easier. If a query suddenly produces millions of rows, developers can immediately recognize whether a Cartesian product was intentional.

Practical Example Scenario
Imagine a training company offering five courses across four cities. To generate a planning matrix of every possible course-city combination, a cross join can combine the courses table with the cities table. This produces twenty combinations, allowing administrators to evaluate logistics and potential scheduling conflicts.
From there, additional constraints such as instructor availability or venue capacity can filter the dataset further. The initial multiplication step creates the framework for deeper decision-making analysis.
Without this SQL technique, developers might resort to nested loops in application code, which is often less efficient than letting the database engine handle relational operations internally.
Optimizing Queries for Large Datasets
When dealing with large tables, consider breaking operations into smaller stages. Temporary tables or Common Table Expressions can isolate manageable subsets before combining them.
It is also beneficial to analyze whether a full Cartesian product is truly required. Sometimes a conditional join or derived table can achieve the same objective with fewer rows generated.
Monitoring query execution time and resource usage is critical in enterprise environments. Database administrators often set limits to prevent runaway queries, particularly those involving cross join operations.
Understanding how your specific database engine handles execution plans, memory allocation, and join strategies can significantly improve performance outcomes.
Conclusion
The cross join is a powerful SQL feature that generates all possible row combinations between tables, enabling complex modeling, simulation, and analytical tasks. While it offers impressive flexibility, it must be used with caution due to its exponential growth potential.
By understanding how Cartesian products work, estimating output sizes, and applying performance best practices, developers can harness its benefits without compromising system stability. When used intentionally and thoughtfully, this SQL operation transforms from a dangerous tool into a strategic advantage for advanced data processing.
Also Read: Wrong Planet: The Shocking Truth Behind Feeling Lost in Today’s World


